DQN-Snake
本科毕业的那个暑假,因为不确定能拿到签证出国,我留在哈工大实验室做助研。当时老师新接了一个横向的项目,是和国防科技大学合作模拟作战,利用RL在scrimmge场景下训练作战策略。在那时我对ML只是一知半解。后来因为训练的成本太高了(实验室的显卡资源不充足),且签证又突然下来了,这个项目也就不了了之。但是对RL有了一个粗略的了解,这几天决定用DQN算法,训练计算机玩一个最经典的游戏—贪吃蛇
Reinforcement Learning Basic
强化学习的基本元素:
- Bisic Element:
Agent,Condition,goal - Main Element:
state,Action,Reward
其主要思想就是计算机控制智能体(Agent),在特定的情境下(condition),达成某个目标(goal)
将这句话翻译成贪吃蛇就是:计算机控制蛇的游戏规则下尽可能地吃更多的果子从而获得尽可能高的分数,在此基础上,问题可以转化为在特定的状态(state),尽可能地采取更优的策略(Action),从而使得期望获得的奖励(Reward)更多
Markov process:
我们可以把游戏类比成马尔可夫决策过程(MDP),即下一个状态只和当前状态有关,而和之前的状态都无关
因此当前状态可以表示为:
S是状态的集合
A是动作的集合
$\gamma$ 是折扣因子
r(s,a)是奖励函数,此时奖励同时取决于状态和动作
p($s^{‘}|s,a)$)是状态转移函数,表示在状态$s_n$执行动作a之后到达状态$s_{n+1}$的概率
Value Function & Bellman Equation
在马尔可夫奖励过程中,一个状态的期望回报被称为这个状态的价值(value)。所有状态的价值就组成了价值函数,价值函数的输入为某个状态,输出为这个状态的价值,表示为$V(s)$
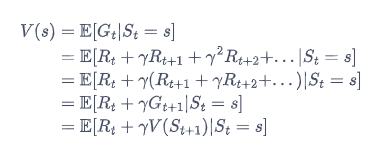
其中,即时的期望就等于即时奖励,既$E[R_{t}|S_{t}]=r(s)$
故可以得到
即贝尔曼方程(Bellman Equation),上式的贝尔曼方程对每一个状态都成立。若一个马尔可夫奖励过程一共有n个状态,即$S=\{s_1,s_2,…,s_n\}$,我们将所有状态的价值表示成一个列向量$V=[V(s_1),V(s_2),…,V(s_n)]^T$,同理奖励函数写成一个列向量$R=[r(s1),r(s2),…,r(s_n)]$。我们可将方程写成矩阵的形式:
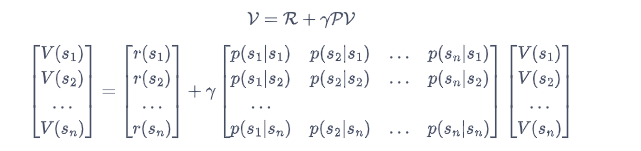
加强学习的目的其实就是为了解这个方程,把每个状态和动作的价值V解出来,即
但是计算的复杂度是$O(n^{3})$,所以对于复杂的系统,使用动态规划,蒙特卡洛法,时序差分法来估计,本文用到的DQN就是基于时序差分法中的Q-Learning启发而来
Q-Leaning
Q-Learning用以下算法来更新动作价值函数Q
实现算法为:
- 初始化Q(s,a)
- 不断进行次如下循环(每个循环是一条序列):
- 得到初始状态s
- 不断进行如下循环直至终止状态(每个循环是序列中的一步)
- 用$\epsilon$-greedy 策略根据选择当前状态s下的动作a
- 得到环境反馈的r,$s^{‘}$
- $Q(s,a)\gets Q(s,a)+\alpha[r+\gamma \max\limits_{a^{‘}}-Q(s^{‘},\alpha)-Q(s,a)]$
- $s \gets s^{‘}$
DQN
上述的Q-Learning算法中Q(s,a)的s和a都是离散的,而实际的应用中,连续的情景无法用简单的表格来记录。因此Google的研究人员就想到了引入神经网络来拟合函数解决复杂的表达问题———DQN(Deep Q-Network),其实质就是用神经网络来表示Q表:
Q-Learning的更新规则:
如果我们希望用神经网络来表示$Q(s,a)$,其实就是希望最后一项尽可能小,因此很自然而然就可以写出Q-Net的损失函数(MSE):
当然,同样使用$\epsilon$-greedy策略来训练
Experience Replay
DQN还有一个特性就是经验回放,意思就是把一部分的经验存放在一个队列中,然后每次训练的时候不断反刍学习之前的经历。
实际训练的tricks
每次训练的查分结果中本身就包括了当前神经网络的输出,在网络更新参数的时候不断的在改变,因此常常使用两套网络,一套(target)用来预测下一个动作,一套(current)用来更新参数,在一定的epochs后,再更新网络(target)
DQN的实现算法:
- 用随机的网络参数w初始化网络$Q_w(s,a)$
- 复制相同的参数 $w^{‘}\gets w$ 初始化目标网络Q_{w^{‘}}
- 初始化经验回放缓冲区R
- for 序列$e=1\rightarrow M$ do
- 获取环境初始状态
- for $t=1->T$ do
- 根据当前网络$Q_w(s,a)$以 $\epsilon$ -greedy 选择动作$a_t$
- 执行动作$a_t$,获得回报$r_t$,环境状态变为$s_{t+1}$
- 将$(s_t,a_t,r_t,s_{t+1})$ 存储进回放缓冲区R
- 若R中数据足够,从R中采样N个数据$(s_i,a_i,r_i,s_{i+1})$
- 对每个数据,用目标网络计算$y_i = r_i+\gamma \max\limits_{a}Q_{w^{‘}}((s_{i+1},a_i))^2$
- 最小化目标损失L,以此更新当前网络
- 更新目标网络
- end for
- end for
Snake Game
游戏规则:
- 蛇在16*16的网格下移动
- 每吃到一次食物体长+1,分数+1
- 碰到边界,咬到身体,活着超过一定时间没吃到食物则判定死亡,游戏结束
网络输入:
- 将蛇头的附近3部内能达到的所有的网格信息作为输入
- 食物的位置信息
- 食物相对蛇头的距离
- 当前时间
- 当前身体长度
共33个输入,4个决策输出(上,下,左,右)
网络超参数;
使用了双隐藏层:
hidden layer1: linear(64,16)+ReLu()
hidden layer2: linear(16,4)+ReLu()
improved DQN
Double DQN
TBC
Dueling DQN
TBC
代码和具体实现见Github